The Three Ways (unfinished)
Aug 1, 2019
TRIGGER
$REDACTED asked Fodder to create a “roadmap to DevOps” plan for The Corporation. $REDACTED was provided with the following rough draft, in an effort to gauge if he was heading down the right path.
RESOURCES
ECO
An outline to DevOps velocity
By STOP DevOps
Overview
This document attempts to outline several paths to DevOps adoption within $REDACTED Monitoring Solutions. It was designed to be as concise as possible; rather than providing too much detail, it attempts to bring to light certain ideas, challenges, and processes.
We present three potential paths to DevOps adoption. The first is a hybrid approach, offering meaningful change while maintaining current architecture and a separation of duties. The second offers a more traditional approach, maintaining a strict separation between business units, and adopting current $REDACTED tooling. The third is a modern approach that requires massive organizational and architectural change, with the potential for massive gains.
Goals
Every project plan must have a defined set of shared goals, so that all parties are moving in the same direction. The below goals are some, but not all, of those goals:
- Reduce waste within build and release pipelines
- Improve stability, speed, and security of all architecture
- Continuously roll-forward, always failing-fast
- Appease all involved business units
- Complete DevOps adoption within 90 days
- Foster a culture that reduces workload, and replaces it with experimentation/learning
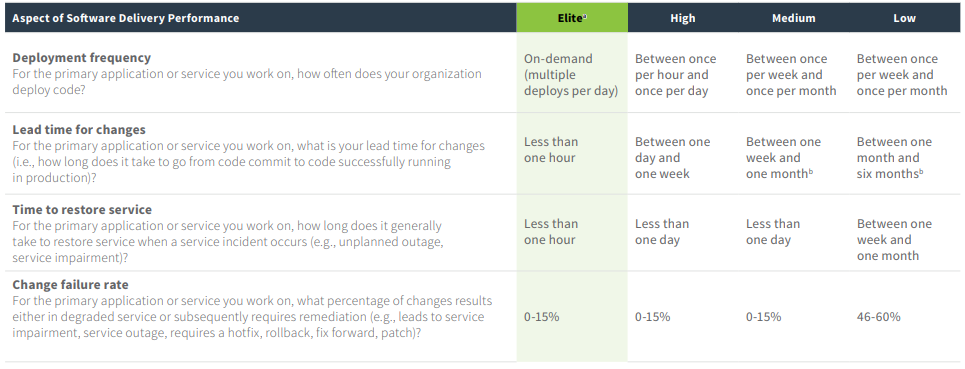
Metrics
DORA (DevOps Research and Assessment) classifies organizations, in part, by using the following criteria:
Terminology
There are several terms that will be shared across most plans. The below definitions will attempt to explain these concepts, from the perspective of our organization.
Concepts
The Three Ways
Briefly, The Three Ways are:
- The First Way: Work always flows in one direction – downstream
- The Second Way: Create, shorten and amplify feedback loops
- The Third Way: Continuous experimentation, to learn from mistakes and achieve mastery
The First Way
The First Way states the following about the flow of work:
- Work should only flow in one direction
- No known defect should be passed downstream
- Always seek to increase the flow

The First Way helps us think of IT as a value stream. Think of a manufacturing line, where each work center adds a component – and thus, value – to the line. Since each work center adds value, it is preferred, that each work center does their part correctly the first time around.
The Second Way
The Second Way describes the feedback process as the following:
- Establish an upstream feedback loop
- Shorten the feedback loop
- Amplify the feedback loop
The Second Way teaches us to think of information as a value-addition. When used correctly, feedback can help to optimize the value stream.
For example:
- Why was there so much wait time at this work center? Resource A was held up.
- Why did this process have to be redone? Because it wasn’t done right the first time.
- “Improving daily work is even more important than doing daily work.” – (Gene Kim, The Phoenix Project: A Novel About IT, DevOps, and Helping Your Business Win)
The Third Way
The Third Way describes environment and culture through the following practices:
- Promote experimentation
- Learn from success and failure
- Constant improvement
- Seek to achieve mastery through practice
The Third Way teaches us that culture and environment are just as important as the work being done. It advocates a culture of experimentation and constant improvement. This results in measured risks and being rewarded for good results.
Continuous Integration
In software engineering, continuous integration (CI) is the practice of merging all developers' working code into a shared mainline several times per day. The main aim of CI is to prevent integration problems, referred to as “integration hell” in in the early days of CI.
CI was originally intended to be used in combination with automated unit tests written through the practices of test-driven development. Initially this was conceived of as running and passing all unit tests in the developer’s local environment before committing to the mainline. This helps avoid one developer’s work-in-progress breaking another developer’s copy. Where necessary, partially complete features can be disabled before committing, using feature toggles for instance.
In addition to automated unit tests, organizations using CI typically use a build server to implement continuous processes of applying quality control in general — small pieces of effort, applied frequently.
Continuous Deployment
Continuous deployment is a strategy for software releases wherein any code commit that passes the testing phase is automatically released into the production environment, making changes that are visible to the software’s users.
Continuous deployment eliminates the human safeguards against unproven code in live software. It should only be implemented when the development and IT teams rigorously adhere to production-ready development practices and thorough testing, and when they apply sophisticated, real-time monitoring in production to discover any issues with new releases.
Continuous Delivery
Continuous delivery (CD or CDE) is a software engineering approach in which teams produce software in short cycles, ensuring that the software can be reliably released at any time and, when releasing the software, doing so manually. It aims at building, testing, and releasing software with greater speed and frequency. The approach helps reduce the cost, time, and risk of delivering changes by allowing for more incremental updates to applications in production. A straightforward and repeatable deployment process is important for continuous delivery.
Configuration Management
Configuration management (CM) is a systems engineering process for establishing and maintaining consistency of a product’s performance, functional, and physical attributes with its requirements, design, and operational information throughout its life. The CM process is widely used by military engineering organizations to manage changes throughout the system lifecycle of complex systems, such as weapon systems, military vehicles, and information systems. Outside the military, the CM process is also used with IT service management as defined by ITIL, and with other domain models in the civil engineering and other industrial engineering segments such as roads, bridges, canals, dams, and buildings.
Containers
Docker is a tool designed to make it easier to create, deploy, and run applications by using containers. Containers allow a developer to package up an application with all the parts it needs, such as libraries and other dependencies, and ship it all in one package.
Containers are isolated from one another and bundle their own software, libraries and configuration files; they can communicate with each other through well-defined channels. All containers are run by a single operating-system kernel and are thus more lightweight than virtual machines. Containers are created from images that specify their precise contents. Images are often created by combining and modifying standard images downloaded from public repositories.
Declarative vs. Imperative languages
Declarative programming is a programming paradigm that expresses the logic of a computation without describing its control flow. Imperative programming is a programming paradigm that uses statements that change a program’s state.
While declarative programming requires a high degree of understanding to create, and imperative programming skills to develop – they are much easier to understand. This facilitates a better, faster knowledge transfer, and a lower barrier to entry.
Infrastructure as Code
One of the key innovations of the DevOps movement is the idea of infrastructure as code. In this paradigm, we reproduce and change the state of our environments in an automated fashion from information in version control rather than configuring infrastructure manually.
This way of working is a natural fit for cloud infrastructure, where resources can be provisioned and configured through APIs. Tools such as Terraform make it simple to provision and evolve cloud infrastructure using declarative, version-controlled configuration. This, in turn, makes provisioning testing and production environments fast and reliable, improving outcomes both for administrators and users of cloud infrastructure. Similar techniques can be used to deploy applications automatically.
In the 2018 “State of DevOps Report”, published by DORA (DevOps Research and Assessment), 44 percent of cloud adopters agreed or strongly agreed that environment configuration and deployments use only scripts and information stored in version control, with no manual steps required (other than approvals). Respondents using infrastructure as code are 1.8 times more likely to be in the elite performance group.
The Twelve-Factor App
In the modern era, software is commonly delivered as a service: called web apps, or software-as-a-service. The twelve-factor app is a methodology for building software-as-a-service apps that:
- Use declarative formats for setup automation, to minimize time and cost for new developers joining the project;
- Have a clean contract with the underlying operating system, offering maximum portability between execution environments;
- Are suitable for deployment on modern cloud platforms, obviating the need for servers and systems administration;
- Minimize divergence between development and production, enabling continuous deployment for maximum agility;
- And can scale up without significant changes to tooling, architecture, or development practices.
The twelve-factor methodology can be applied to apps written in any programming language, and which use any combination of backing services (database, queue, memory cache, etc).
Tools
- Docker
- Kubernetes
- Bitbucket
- Terraform
- Packer
- Vault
- Helm
- Helmfile
- Vagrant
- KitchenCI
- Semantic-Release
- Bamboo
- Minikube
Where we stand
STOP has adopted few discernable DevOps practices today. STOP is lacking in several key areas:
- Dev/Ops team cohesion
- Development velocity
- Automated testing
- Infrastructure-as-code
- No-fault design and processes
- A culture of learning and experimentation
Successes
Change Management is an important process
The main goal of any change management process is to ensure that changes are managed in a cohesive way, ensuring that there are checks and balances to establish and support the implemented enterprise operational model around user impact, corporate policies, regulatory compliance and security. In order to achieve this goal, the change management process needs to determine how changes are to be managed, what techniques are to be applied, and what methodologies are to be used.
Monitoring processes are very good
STOP monitoring processes are robust and effective. Time-series monitoring performed by the PerlTools application, in particular, is in-line with modern best practices. Orion (poll-based) monitoring is similarly effective, though this type of monitoring is considered to be “old” by many DevOps organizations. This type of monitoring tends to be complex to manage, and it leads to notification overload. Conversely, time-series based monitoring leverages logic to minimize alerts and perform automated remediation.
Core applications are well-designed
The fundamental components of the $REDACTED application are generally well-designed. They are simple to install, spawn isolated services on a single port, are configured via environment variables, and will heal in the event of a failure.
Problems
Anti-Type B: DevOps Team Silo
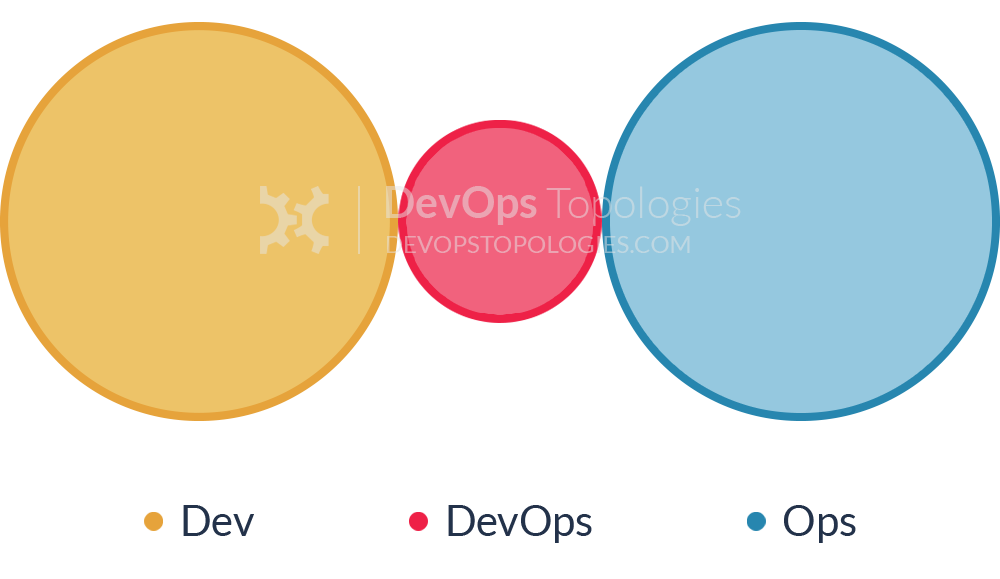
The DevOps Team Silo (Anti-Type B) typically results from a manager or exec deciding that they “need a bit of this DevOps thing” and starting a ‘DevOps team’ (probably full of people known as ‘a DevOp‘). The members of the DevOps team quickly form another silo, keeping Dev and Ops further apart than ever as they defend their corner, skills, and toolset from the ‘clueless Devs’ and ‘dinosaur Ops’ people.
The only situation where a separate DevOps silo really makes sense is when the team is temporary, lasting less than (say) 12 or 18 months, with the express purpose of bringing Dev and Ops closer together, and with a clear mandate to make the DevOps team superfluous after that time; this becomes what I have called a Type 5 DevOps Topology.– (source: https://web.devopstopologies.com/)
RPMs were not designed to perform configuration management
STOP currently bundles required configurations for each environment into RPM packages, along with the app. This is a bad practice that has led to a need for different RPM packages (for the same app) in different environments.
A better practice is to build a single artifact, performing configuration outside of the package itself.
Security as an afterthought (and somebody else’s problem)
Poor package management has led to a lack of security with the STOP architecture. Because security was not built-into the build and release process, it is overlooked by both the developers and $REDACTED’ security teams.
A better practice is to build security alongside the app, in version control, where it may be reviewed by the proper teams. Secrets should be managed outside of RPM packages – and default credentials should NEVER be used in production environments.
Attachment to mutable infrastructure and processes
$REDACTED has built a platform around the concepts of configuration management, which is a type of tooling that many DevOps organizations are moving away from completely. Configuration management reinforces the practice of building mutable (can be changed) environments, whereas immutable (unchanging) architectures are better suited to DevOps.
A mutable infrastructure can be broken – leading to re-work, just to return to a “normal” state. Conversely, immutable infrastructures lend themselves to proper version control, ease of rolling forward/backward, and consistent environmental behaviors.
Retroactive development patterns are antithetical to DevOps
Similar to the above problem, standing environments – coupled with configuration management - lends itself to broken applications. Rather than rebuilding and retrying, developers are left to troubleshoot application problems – rather than performing more important work.
Ephemeral development environments, coupled with strict dev/prod parity, lead to consistent, clean environments that rarely require troubleshooting. When they do, issues are easily replicated in lower environments.
Over-the-wall development leads to excessive rework
Knowledge silos and separations of duty within STOP leads to a culture of fear, mistrust, and the “guarding of one’s territory.” Developers and Operations personnel have little to no relationship. A lack of trust leads to extensive email chains, explanation and re-explanation to make anything happen, and flat-out (sometimes arbitrary) barriers placed into workflows.
A better practice is to bring disparate teams together, to foster a culture of trust and understanding. More than anything, freedom to experiment and collaborate can enable this type of organizational change.
A large percentage of code is not version-controlled at all
Some believe that scripting is a DevOps solution. It’s not (necessarily). Automation without proper version control, automated testing, standardized deployments and declarative formats can, in many instances, increase complexity – not simplify it.
Imperative solutions are being presented as DevOps successes
This is a mistake. Declarative programming leads to more immutable, easier-to-understand infrastructures. While imperative programming provides the underlying logic for any good declarative tool, it also leads to complexity when used for every problem. Imperative programming/scripting requires logic and specialized knowledge in order to deal with edge-cases and failure states. By contrast, declarative languages provide a higher-level understanding of the underlying logic, are easier to learn, and add an element of trust; users of declarative solutions can generally “trust” that their software will behave as expected.
Assumptions
All the below plans assume that the following is true:
- The organization will systematically attack individual service areas over time, rather than attempting to fix every system at once.
- This document will outline a 90-day plan to integrate a single service (i.e. “the gateways”). Once a single service has been migrated, future services will be much easier and faster to migrate.
- The organization will be unable – and should not be expected to – plan for every possible change. In a DevOps organization, change happens organically, and plans are generated automatically.
Planning
Below are several plans that will attempt to outline a path to DevOps success. Not all plans are created equal.
Plan 1: The hybrid route
Complexity: Low
Chance of success: High
Max Twelve-Factor Targets: 12
Description
The optimal route would have the organization adopt modern technologies that enable organizational change, while maintaining current system architecture. The argument for this path is one of skill; we are not yet ready to implement a full container-based architecture, and the benefits/need for one has not yet been justified.
On a hybrid approach:
“Perfect is the enemy of good.” - Voltaire
Advantages
- Ease of adoption
- Does not usurp the power of Ops or Security
- Fails fast
Disadvantages
- Will require a closer relationship with Ops and Security
Requirements
- Docker
- Bitbucket
- Semantic-Release
- Packer
- Terraform
- Vagrant
- KitchenCI
- Bamboo
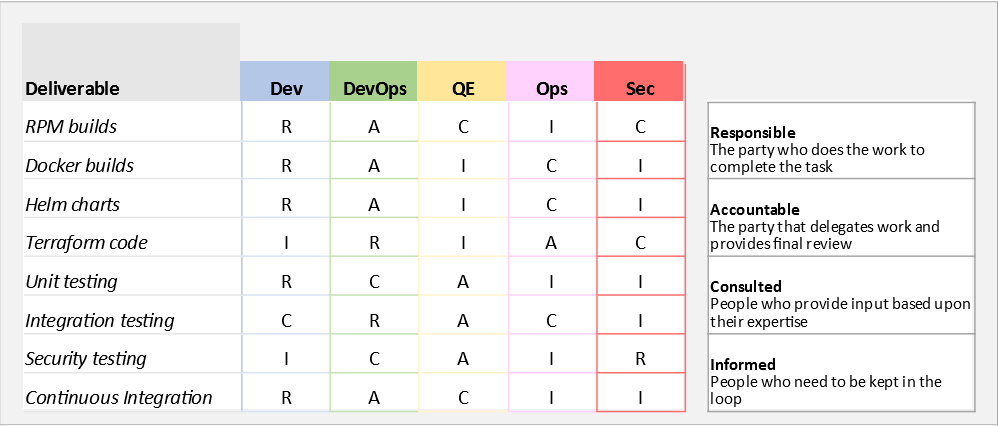
Responsibilities
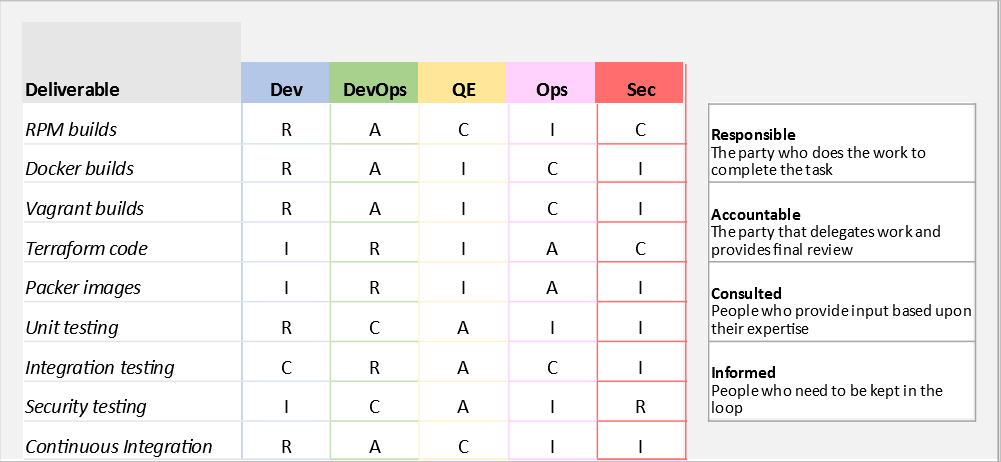
Timeline
- Phase 1 (90 days)
- Create a standard Docker image that can be used by developers and CI pipelines to build/test RPM packages.
- Work with Operations to develop a standard set of Packer images and Terraform modules to be used for infrastructure deployments.
- Work with Security to develop a standard set of Integration tests.
- Target a service to improve (i.e. “the gateways”). Identify any required dependencies, and work on those services first.
- Implement a local Docker and/or Vagrant environment to run the service.
- Implement Terraform configuration to allow developers to deploy Packer images and application code into lower environments.
- Implement Terraform code in CI pipelines, automating deployments to all environments.
- Implement controls within the CI pipeline to allow for fast failure; unit testing for developers, integration testing for Operations and Security.
- Implement automated semantic versioning within the CI pipeline.
- Train employees in the new development practices.
- Phase 2 (14-day cycles)
- Repeat steps 4 through 10 until all or most services have been migrated.
Topology
Type 1: Dev and Ops Collaboration
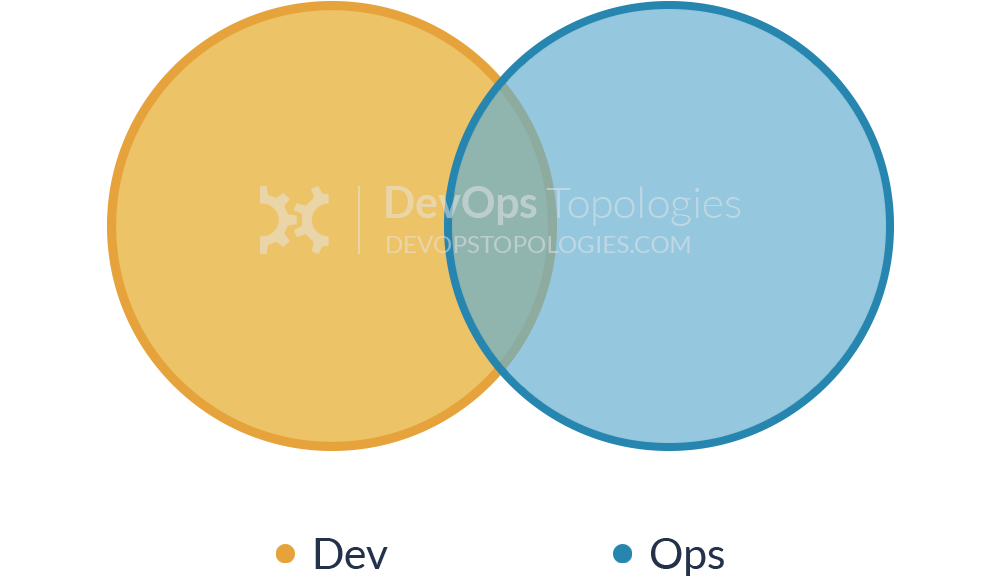
This is the ‘promised land’ of DevOps: smooth collaboration between Dev teams and Ops teams, each specialising where needed, but also sharing where needed. There are likely many separate Dev teams, each working on a separate or semi-separate product stack.
My sense is that this Type 1 model needs quite substantial organisational change to establish it, and a good degree of competence higher up in the technical management team. Dev and Ops must have a clearly expressed and demonstrably effective shared goal (‘Delivering Reliable, Frequent Changes’, or whatever). Ops folks must be comfortable pairing with Devs and get to grips with test-driven coding and Git, and Devs must take operational features seriously and seek out Ops people for input into logging implementations, and so on, all of which needs quite a culture change from the recent past. – (source: https://web.devopstopologies.com/)
Process
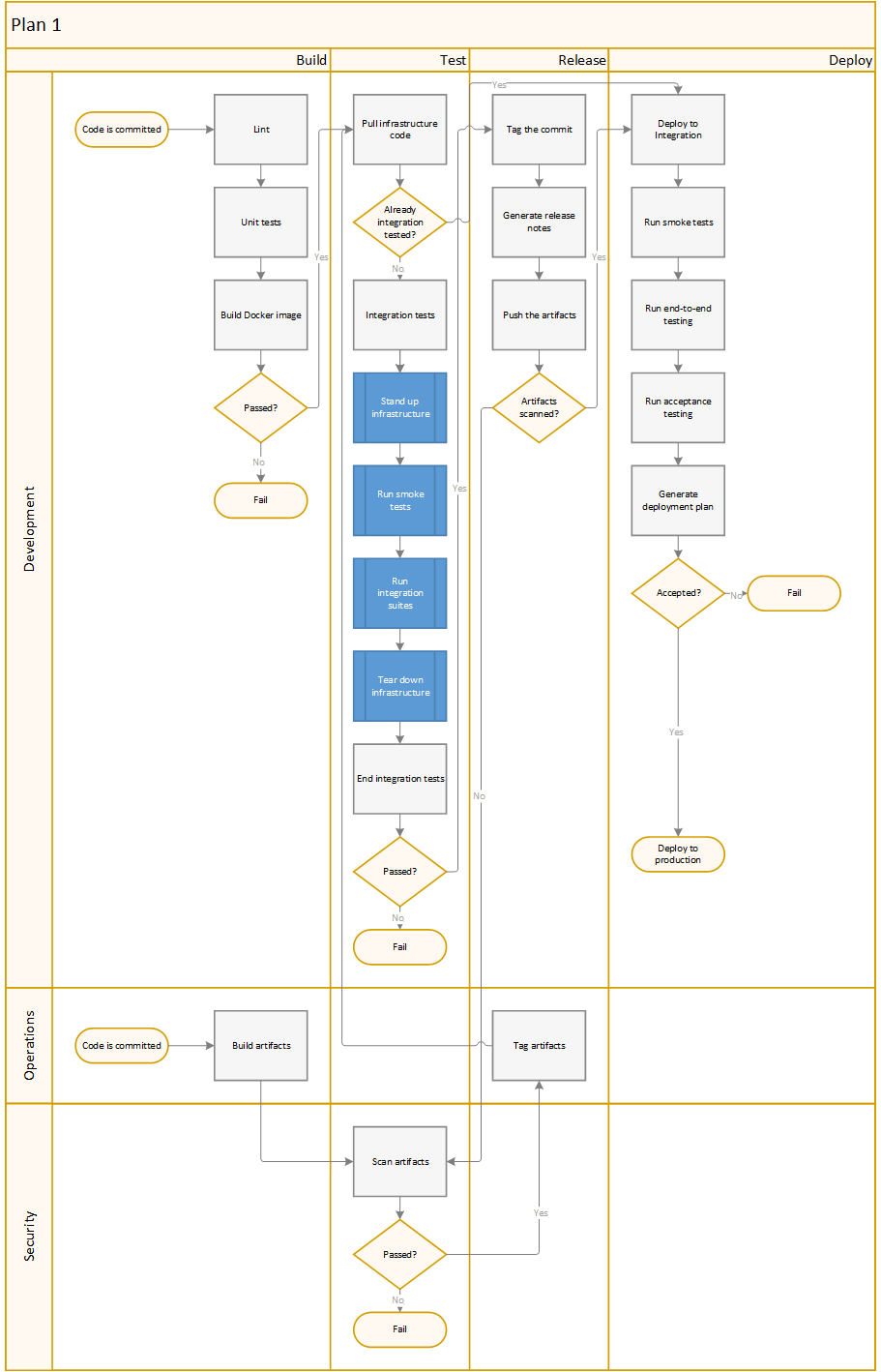
Expenses
- Terraform Enterprise - $???
- DORA Assessment - $40k
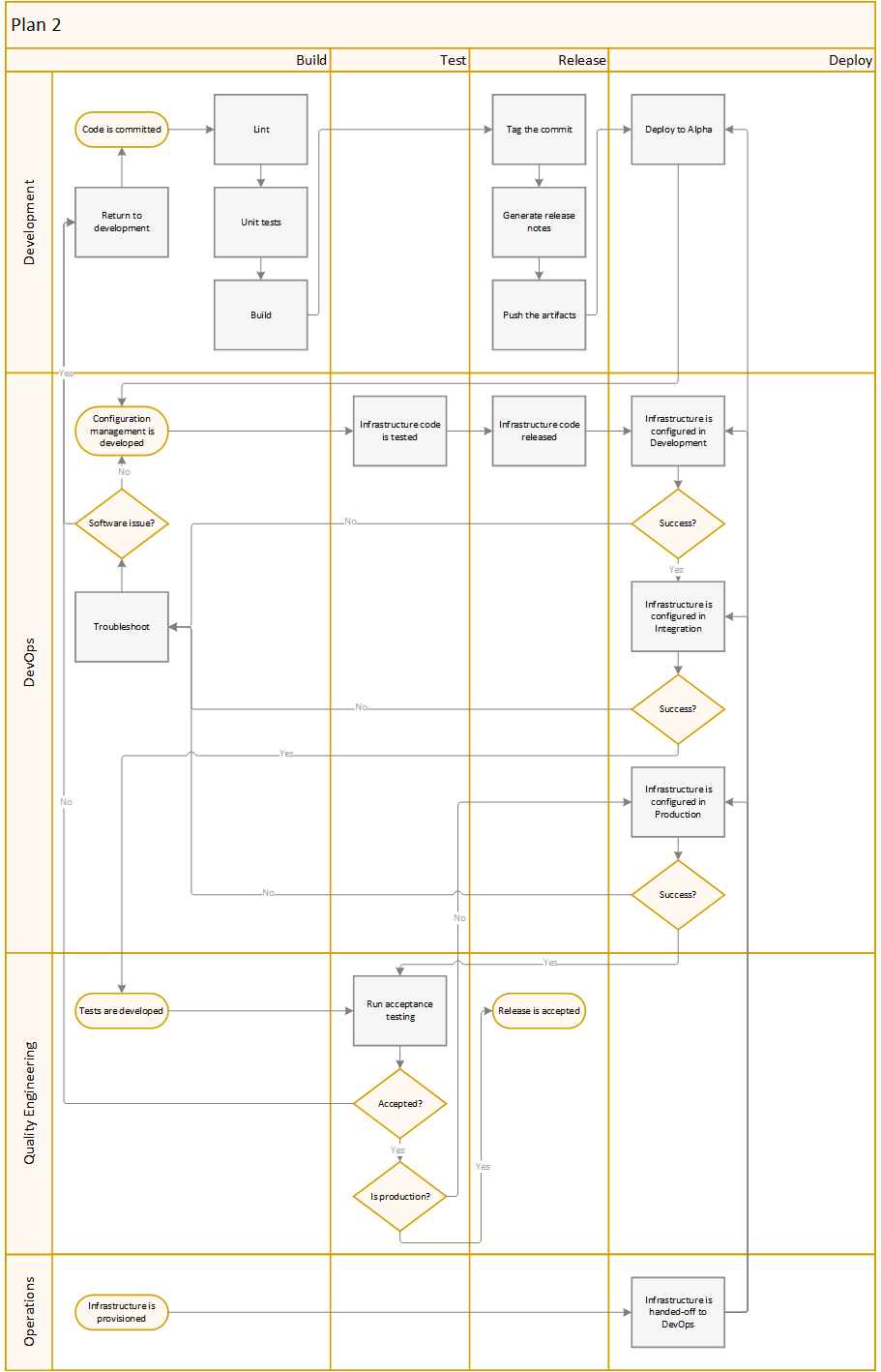
Plan 2: The traditional route
Complexity: Medium
Chance of success: Medium
Max Twelve-Factor Targets: 6
Description
This is the route that assumes we will be running “business as usual.” In effect, we will introduce little new tooling or processes, in an effort to respect corporate traditions.
In this model, DevOps would utilize Saltstack to automate-away the most common tasks. Developers are required to build/test/release their own code, before handing it off to DevOps for Change Management. Operations would be mostly uninvolved (except to modify settings that Dev/DevOps are not allowed to touch, and to provision new infrastructure.)
On servers as pets:
“Servers or server pairs that are treated as indispensable or unique systems that can never be down. Typically, they are manually built, managed, and “hand fed”. Examples include mainframes, solitary servers, HA loadbalancers/firewalls (active/active or active/passive), database systems designed as master/slave (active/passive), and so on.” – (Randy Bias, “Chronicles of History”)
Advantages
- Ease of adoption
- Requires little from other teams
Disadvantages
- This plan does not attempt to achieve most DevOps principles
- Infrastructure managed in this way requires extensive development efforts
- Infrastructure cannot be provisioned, destroyed, or rebuilt without involving Operations directly
- Developers will find configuration management limiting
- This design provides no failure states for Developers or DevOps. Rather than immediate feedback, problems are “thrown backwards” through the chain of departments involved.
Requirements
- Bitbucket
- Salt
- Bamboo
Responsibilities
Timeline
- Phase 1 (90 days)
- Target a service to improve (i.e. “the gateways”). Identify any required dependencies, and work on those services first.
- Implement standardized RPM builds within a CI pipeline.
- Develop Saltstack code that can be used to deploy packages and configuration into shared development environments.
- Address problems as they arise during deployments. Create application or CM code to handle failure states automatically.
- Configure Salt Master to apply changes in higher environments.
- Train employees in the new development practices.
- Phase 2 (14-day cycles)
- Repeat steps 1 through 6 until all or most services have been migrated.
Topology
Type 7: SRE Team (Google Model)
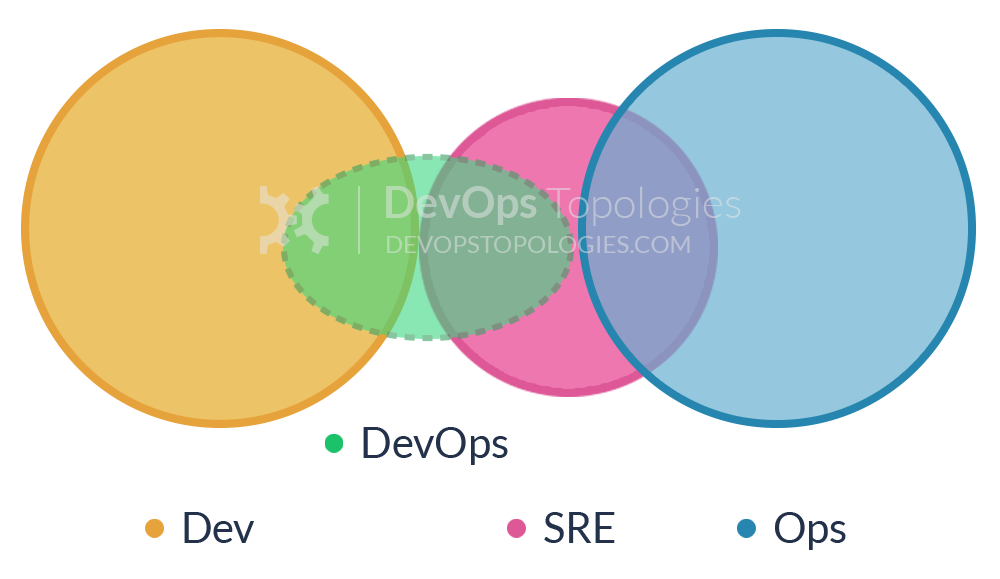
NOTE: Replace “SRE” with “Change Management” and this example will make more sense.
DevOps often recommends that Dev teams join the on-call rotation, but it’s not essential. In fact, some organisations (including Google) run a different model, with an explicit ‘hand-off’ from Development to the team that runs the software, the Site Reliability Engineering (SRE) team. In this model, the Dev teams need to provide test evidence (logs, metrics, etc.) to the SRE team showing that their software is of a good enough standard to be supported by the SRE team.
Crucially, the SRE team can reject software that is operationally substandard, asking the Developers to improve the code before it is put into Production. Collaboration between Dev and SRE happens around operational criteria but once the SRE team is happy with the code, they (and not the Dev team) support it in Production. – (source: https://web.devopstopologies.com/)
Process
Expenses
- DORA Assessment - $40k
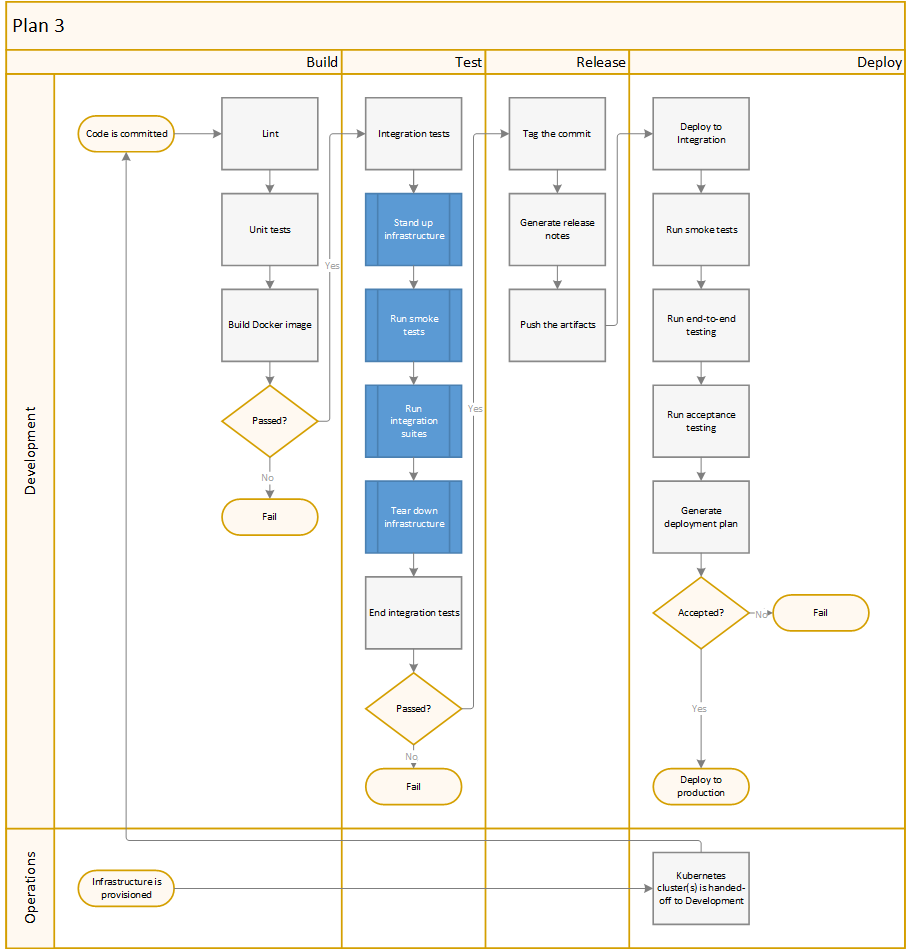
Plan 3: The container route
Complexity: High
Chance of success: Medium-High
Max Twelve-Factor Targets: 12
Description
This route assumes that STOP will go all-in with the latest and greatest technologies. We will spare no expense, hiring contractors to implement new software, design new processes, and train our employees to become Agile.
In this model, developers would utilize container technology to build-out consistent, reproducible application architectures. Ops would manage a Kubernetes cluster – complete with all the security, policy, and separation of duties that they need. DevOps would be responsible for the build/test/release/deploy of said applications into the cluster.
On servers as cattle:
“Arrays of more than two servers, that are built using automated tools, and are designed for failure, where no one, two, or even three servers are irreplaceable. Typically, during failure events no human intervention is required as the array exhibits attributes of “routing around failures” by restarting failed servers or replicating data through strategies like triple replication or erasure coding. Examples include web server arrays, multi-master datastores such as Cassandra clusters, multiple racks of gear put together in clusters, and just about anything that is load-balanced and multi-master.” – (Randy Bias, “Chronicles of History”)
Advantages
- Has the potential to truly revolutionize development, operations, and security
- Grants Developers and DevOps much more freedom than they have today
- Fails very fast
Disadvantages
- Kubernetes is complex
- Will be slow to adopt, and slow to master
- Is likely to be expensive
Requirements
- Bitbucket
- Salt
- Docker
- Kubernetes
- Minikube
- Helm
- Helmfile
- Semantic-Release
- Terraform
- KitchenCI
- Bamboo
Responsibilities
Timeline
- Phase 1 (90 days)
- Create a standard Docker image that can be used by developers and CI pipelines to build/test RPM packages.
- Work with Operations to develop a standard set of Terraform modules to be used for infrastructure deployments (DNS record changes, Kubernetes service accounts, etc.)
- Work with Operations to deploy Kubernetes cluster(s) into the network.
- Work with Security to develop a standard set of Integration tests.
- Target a service to improve (i.e. “the gateways”). Identify any required dependencies, and work on those services first.
- Build a Docker container to run the service.
- Package the container into a Helm chart.
- Configure Helmfile to deploy the Helm chart.
- Implement Terraform configuration to allow developers to deploy Helm charts into Minikube.
- Implement Terraform configuration to allow developers to deploy Helm charts into lower environments.
- Implement Terraform code and Helm charts in CI pipelines, automating deployments to all environments.
- Implement controls within the CI pipeline to allow for fast failure; unit testing for developers, integration testing for Operations and Security.
- Implement automated semantic versioning within the CI pipeline.
- Train employees in the new development practices.
- Phase 2 (14-day cycles)
- Repeat steps 5 through 14 until all or most services have been migrated.
Topology
Type 8: Container-Driven Collaboration
Containers remove the need for some kinds of collaboration between Dev and Ops by encapsulating the deployment and runtime requirements of an app into a container. In this way, the container acts as a boundary on the responsibilities of both Dev and Ops. With a sound engineering culture, the Container-Driven Collaboration model works well, but if Dev starts to ignore operational considerations this model can revert towards to an adversarial ‘us and them’. – (source: https://web.devopstopologies.com/)
Process
Expenses
- Openshift Kubernetes - $???
- DORA Assessment - $40k
- Terraform Enterprise - $???
Shared Plans
Pipelines
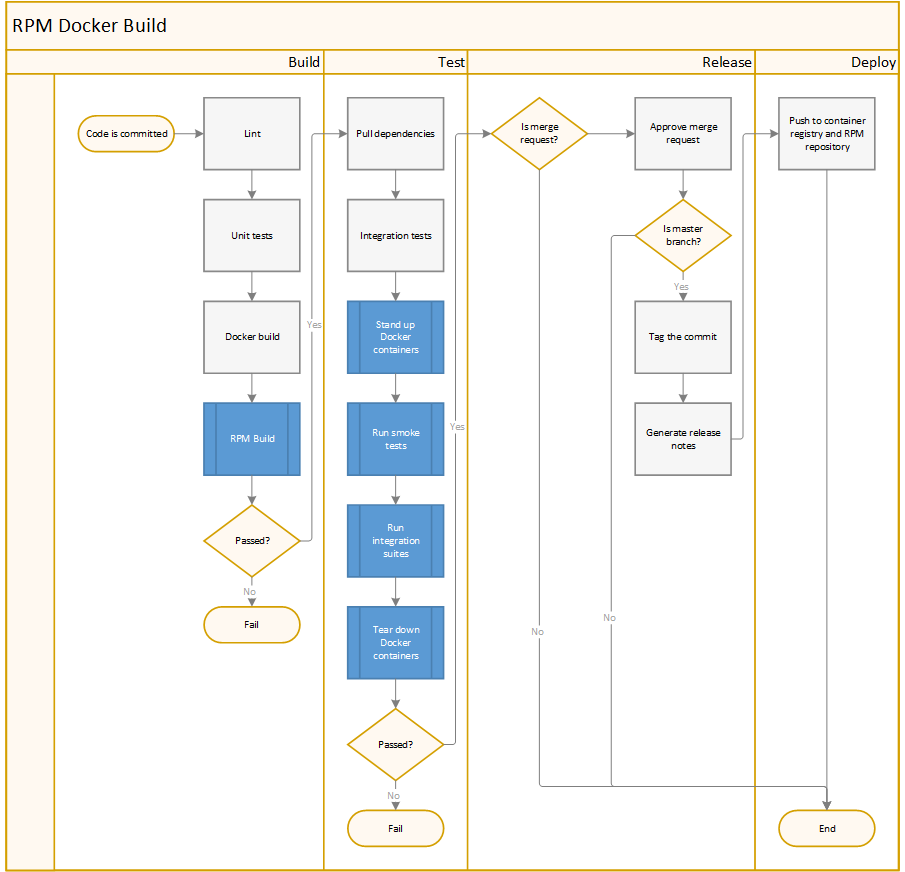
RPM Docker Build
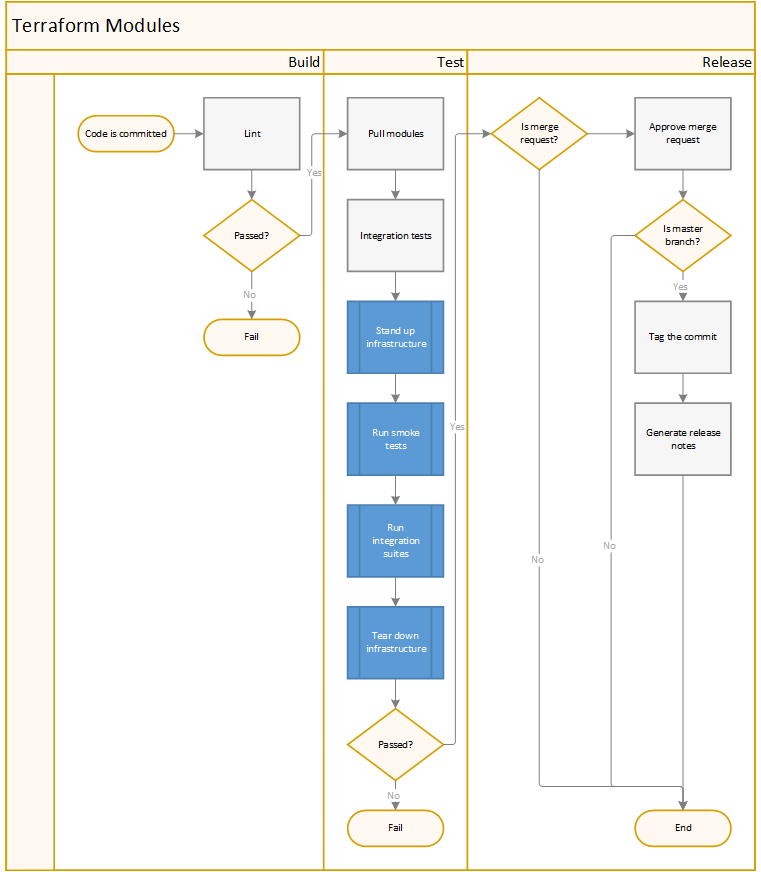
Terraform Modules
Terraform Deployments

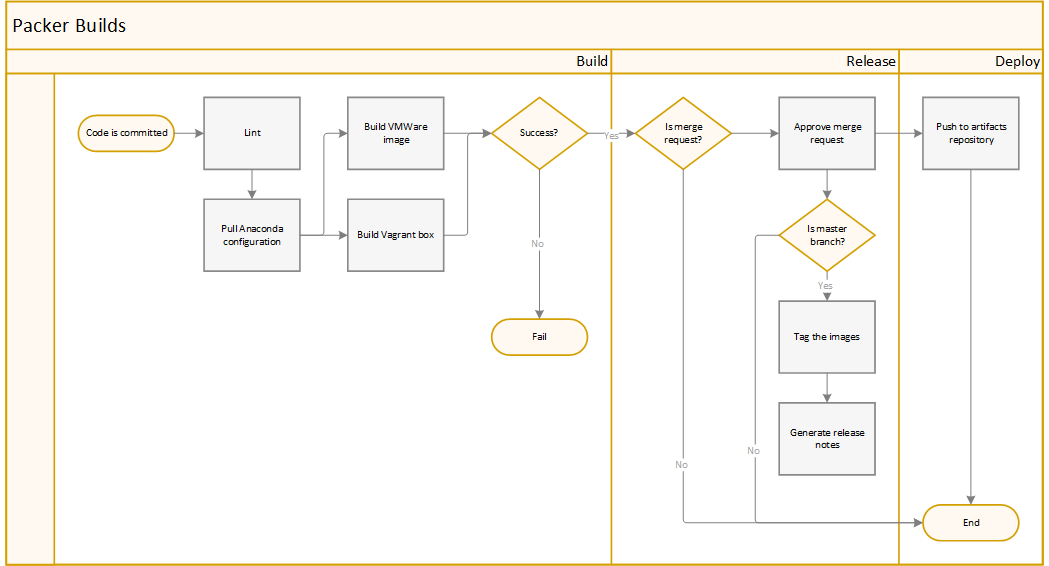
Packer Builds
Conclusion
In conclusion, there are many paths to DevOps success – and some are better than others. There are many more not listed here (such as a cloud-first mentality, microservices architecture, and monolithic deployments). The three options presented here, succinctly, were meant to represent:
- Plan 1: An option that is easy to adopt, and provides true organizational change
- Plan 2: An option that maintains the status-quo, offering a longer-term path to adoption
- Plan 3: An option that is one the best – if not the best – option available today
These plans are by no means comprehensive – and they never could be. DevOps is an evolving process, a mentality, and a shared vision. To truly succeed at DevOps, and organization must be comfortable with exploring the unknown.
CAT
data.stats.symptoms = [
- agitation
- frustration
]
ECHO
Upon presenting this to $REDACTED, Fodder was met with a swift, “What the hell is this?”